Hadoop Workload Analysis
We have analyzed Hadoop workloads from three different research clusters from a user-centric perspective. The goal is to better understand data scientists' use of the system and how well the use of the system matches its design.
Overall, our analysis suggests that Hadoop usage is still in its adolescence. We do see good use of Hadoop: all workloads are dominated by data transformations that Hadoop handles well; users leverage Hadoop's ability to process massive-scale datasets; customizations are used in a visible fraction of jobs for correctness or performance reasons. However, we also find uses that go beyond what Hadoop has been designed to handle:
- There are a significant number of independent, small-scale jobs that may be amenable to simpler, non-Hadoop solutions.
- Surprisingly few users are using higher-level declarative frameworks, though some are constructing "manual" workflows.
- Workloads are highly diverse, suggesting the need to effectively author and efficiently execute a large variety of applications.
- Significant performance penalties are arising from over-reliance on default configuration parameters.
In summary, we find that users today make good use of their Hadoop clusters, but there is also significant room for improvement in how users interact with them:
- Improving the effectiveness of authoring and the efficiency of executing diverse workloads,
- improving inter-activity,
- better user education, and
- automatic optimization and tuning of complex applications.
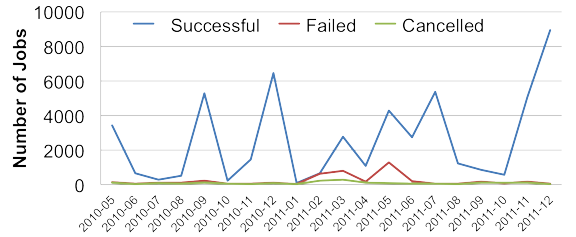
OpenCloud Log Statistics (Total User: 78)
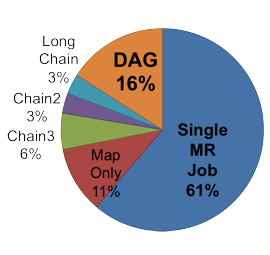
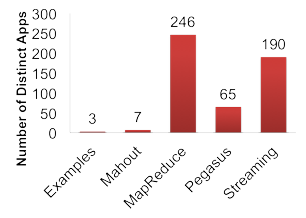
Distribution of Job Structures and Application Frameworks in OpenCloud Logs
People
FACULTY
Garth Gibson
GRAD STUDENTS
Kai Ren
Publications
- Hadoop Log Dataset Release - download page
- Hadoop's Adolescence: An Analysis of Hadoop Usage in Scientific Workloads. Kai Ren, YongChul Kwon, Magdalena Balazinska, Bill Howe. Very Large Data Bases (VLDB), 2013.
Abstract / PDF [986K]
Acknowledgements
We thank N. Balasubramanian and M. Schmitz for helpful comments and discussions. We also thank the owners of the logs from the three Hadoop clusters for graciously sharing these logs with us. This research is supported in part by The Gordon and Betty Moore Foundation, National Science Foundation under awards, SCI-0430781, CCF-1019104. Qatar National Research Foundation 09-1116-1-172, DOE/Los Alamos National Laboratory, under contract number DE-AC52- 06NA25396/161465-1, by Intel as part of ISTC-CC.
We thank the members and companies of the PDL Consortium: Amazon, Datadog, Google, Honda, Intel Corporation, IBM, Jane Street, Meta, Microsoft Research, Oracle Corporation, Pure Storage, Salesforce, Samsung Semiconductor Inc., Two Sigma, and Western Digital for their interest, insights, feedback, and support.