PLFS
Component failures are a frequent event. These failures are particularly problematic as many applications at LANL, and other High Performance Computing (HPC) sites, have long run times in excess of days, weeks, and even months. Typically these applications protect themselves against failure by periodically checkpointing their progress, saving the state of the application to persistent storage. After a failure the application can then restart from the most recent checkpoint. For many applications, saving this state into a shared single file is most convenient. With such an approach, the size of writes are often small and not aligned with file system boundaries. Unfortunately for these applications, this preferred data layout results in pathologically poor performance from the underlying file system, which is optimized for large, aligned writes to non-shared files.
We posit that an interposition layer inserted into the existing storage stack can rearrange problematic access patterns to achieve much better performance from the underlying parallel file system. To test this, we have developed PLFS, a Parallel Log-structured File System, to act as this layer. Measurements using PLFS on several synthetic benchmarks and real applications at multiple HPC supercomputing centers (including Roadrunner, the largest supercomputer LANL has ever had) confirm our hypothesis: writing to the underlying parallel file system through PLFS improves checkpoint bandwidth for all tested applications and benchmarks and on all three studied parallel file systems; in some cases, bandwidth is raised by several orders of magnitude (Figure 1).
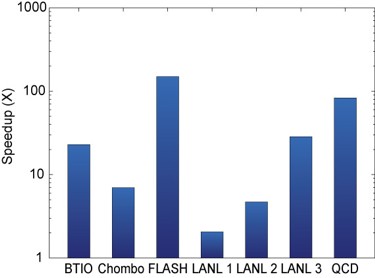
Figure 1 - Summary of results. This graph summarizes our results which are be explained in detail in our research report. The key ob servation here is that our technique has im proved checkpoint bandwidths for all seven studied benchmarks and applications by up to several orders of magnitude.
From a file system perspective, there are two basic checkpointing patterns: N-N and N-1. An N-N checkpoint is one in which each of N processes writes to a unique file, for a total of N files written. An N-1 checkpoint differs in that all of N processes write to a single shared file. Applications using N-N checkpoints usually write sequentially to each file, an access pattern ideally suited to parallel file systems. Conversely, applications using N-1 checkpoint files typically organize the collected state of all N processes in some application specific, canonical order, often resulting in small, unaligned, interspersed writes. Some N-1 checkpoint files are logically the equivalent of concatenating the files of an N-N checkpoint (i.e. each process has its own unique region within the shared file). This is referred to as an N-1 segmented checkpoint file and is extremely rare in practice. More common is an N-1 strided checkpoint file in which the processes write multiple small regions at many different offsets within the file; these offsets are typically not aligned with file system block boundaries. N-1 strided checkpointing applications often make roughly synchronous progress such that all the processes tend to write to the same region within the file concurrently, and collectively this region sweeps across the file.
Since N-N checkpointing derives higher bandwidth than N-1, the obvious path to faster checkpointing is for application developers to rewrite existing N-1 checkpointing applications to do N-N checkpointing instead. Additionally, all new applications should be written to take advantage of the higher bandwidth available to N-N checkpointing. Although some developers have gone this route, many continue to prefer an N-1 pattern because of several advantages, even though its disadvantages are well understood. One, a single file is much easier to manage and to archive. Two, N-1 files usually organize data into an application specific canonical order that commonly aggregates related data together in contiguous regions, making visualization of intermediate state simple and efficient. Additionally, following a failure, a restart on a different number of compute nodes is easier to code as the checkpoint format is independent of the number of processes that captured the checkpoint; conversely, gathering the appropriate regions from multiple files or from multiple regions within a single file is more complicated. Thus, developing a method by which an N-1 pattern can achieve the bandwidth of an N-N pattern while still benefiting from N-1 advantages would be worthwhile.
We began with the hypothesis that an interposition layer can transparently rearrange an N-1 checkpoint pattern into an N-N pattern and thereby decrease checkpoint time by taking advantage of the increased bandwidth achievable via an N-N pattern. To test this, we have developed such an interposition layer, PLFS, designed specifically for large parallel N-1 checkpoint files. The basic architecture is illustrated in Figure 2. PLFS is a virtual file system situated between the parallel application and an underlying parallel file system responsible for the actual data storage. As PLFS is a virtual file system, it leverages many of the services provided by the underlying parallel file system such as redundancy, high availability, and a globally distributed data store. This frees PLFS to focus on just one specialized task: rearranging application data so the N-1 write pattern is better suited for the underlying parallel file system.
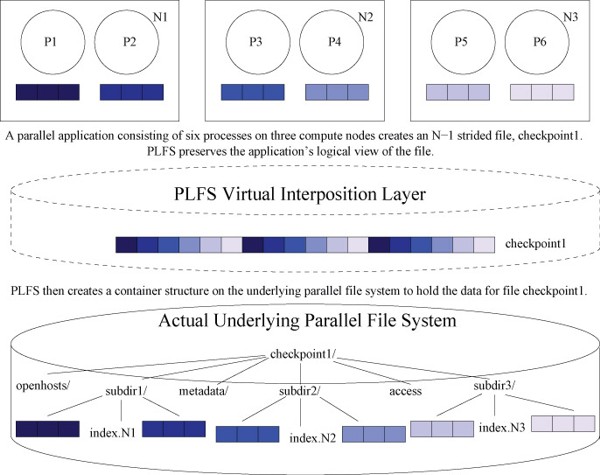
Figure 2 - PLFSData Reorganization. This figure depicts how PLFS reorganizes an N-1 strided checkpoint file onto the underlying parallel file system. A parallel application consisting of six processes on three compute nodes is represented by the top three boxes. Each box represents a compute node, a circle is a process, and the three small boxes below each process represent the state of that process. The processes create a new file on PLFS called checkpoint1, causing PLFS in turn to create a container structure on the underlying parallel file system. The container consists of a top-level directory also called checkpoint1 and several sub-directories to store the application’s data. For each process opening the file, PLFS creates a data file within one of the sub-directories, it also creates one index file within that same sub-directory which is shared by all processes on a compute node. For each write, PLFS appends the data to the corresponding data file and appends a record into the appropriate index file. This record contains the length of the write, its logical offset, and a pointer to its physical offset within the data file to which it was appended. To satisfy reads, PLFS aggregates these index files to create a lookup table for the logical file. Also shown in this figure are the access file, which is used to store ownership and privilege information about the logical file, and the openhosts and metadata sub-directories which are used to cache metadata in order to improve query time (e.g. a stat call).
Basically, for every logical PLFS file created, PLFS creates a container structure on the underlying parallel file system. Internally, the basic structure of a container is a hierarchical directory tree consisting of a single top-level directory and multiple sub-directories that appears to users; PLFS builds a logical view of a single file from this container structure. Multiple processes opening the same logical file for writing share the container although each open gets a unique data file within the container into which all of its writes are appended. By giving each writing process in a parallel application access to a non-shared data file, PLFS converts an N-1 write access pattern into a N-N write access pattern. When the process writes to the file, the write is appended to its data file and a record identifying the write is appended to an index file.
Figures 3a, b, and c present some of the results of our study using the LANL synthetic checkpoint tool, MPI-IO Test on three different parallel file systems, PanFS, GPFS, and Lustre. For each of these graphs, the size of each write was 47001 bytes (a small, unaligned number observed in actual applications to be particularly problematic for file systems). Writes were issued until two minutes had elapsed. Although this is atypical since applications tend to write a fixed amount of data instead of writing for a fixed amount of time, we have observed that this allows representative bandwidth measurements with a predictable runtime. These are the same three graphs that we presented in Figure 2, except that a third line has been added to each. The three lines show the bandwidth achieved by writing an N-N pattern directly to the underlying parallel file system, the bandwidth achieved by writing an N-1 pattern directly to the underlying parallel file system, and the third line is the bandwidth achieved by writing an N-1 pattern indirectly to the underlying parallel file system through PLFS. These graphs illustrate how the performance discrepancy between N-N and N-1 checkpoint patterns is common across PanFS, GPFS, and Lustre. We see that particularly for the PanFS results, which were run on our Roadrunner supercomputer, PLFS achieves the full bandwidth of an N-N pattern (i.e. up to about 31 GB/s). In fact, for several of the points, an N-1 pattern on PLFS actually outperforms an N-N pattern written directly to PanFS.
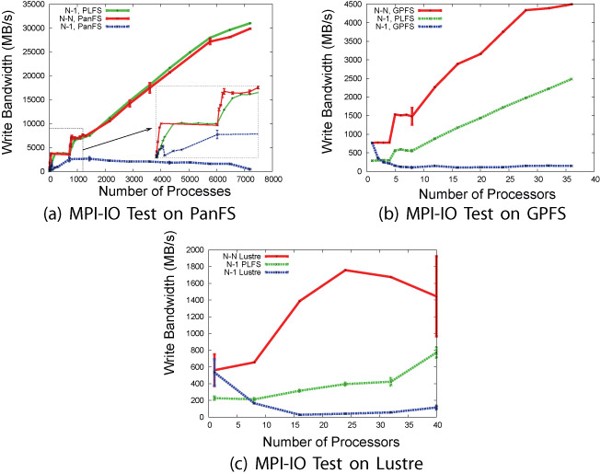
Figure 3 - Experimental Results. These three graphs demonstrate the large discrepancy between achievable bandwidth and scalability using N-N and N-1 checkpoint patterns on three of the major HPC parallel file systems.The greenl line shows how PLFS allows an N-1 checkpoint to achieve most, if not all, of the bandwidth available to an N-N checkpoint.
People
Los Alamos National Laboratory
Carnegie Mellon University
- Garth Gibson
- Chuck Cranor
EMC
- John Bent
Publications & Downloads
- PLFS source code
- Structuring PLFS for Extensibility.
Chuck Cranor,
Milo Polte,
Garth Gibson. 8th Parallel Data Storage Workshop, Nov 18, 2013, Denver, CO.
Abstract / PDF [302K]
- Parallel Log Structured File System (PLFS). Gary Grider, John Bent, Chuck Cranor, Jun He, Aaron Torres, Meghan McClelland, Brett Kettering. In Science Highlights: Theory, Simulation, and Computation Directorate. Los Alamos National Laboratory Associate Directorate for Theory, Simulation, and Computation (ADTSC) LA-UR 13-20839, 2013.
Abstract / PDF [136K]
- I/O Acceleration with Pattern Detection. Jun He, John Bent, Aaron Torres, Gary Grider, Garth Gibson, Carlos Maltzahn, Xian-He Sun. HPDC '13. Proceedings of the 22nd International Symposium on High-performance Parallel And Distributed Computing, June 17-21, 2013.
Abstract / PDF [597K]
- HPC Computation on Hadoop Storage with PLFS. Chuck Cranor, Milo Polte, Garth Gibson. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-12-115. Nov. 2012.
Abstract / PDF [170K]
- Reducing Concurrency Bottlenecks in Parallel I/O Workloads. Adam Manzanares, John Bent, Meghan Wingate, Milo Polte, Garth Gibson. Los Alamos Technical Report LA-UR-11-10426, November 2012.
Abstract / PDF [259K]
- Discovering Structure in Unstructured I/O. Jun He, John Bent, Aaron Torres, Gary Grider, Garth Gibson, Carlos Maltzahn, Xian-He Sun. 7th Parallel Data Storage Workshop. Salt Lake City, UT, November 12, 2012.
Abstract / PDF [411K]
- A Plugin for HDF5 Using PLFS For Improved I/O Performance. Kshitij Mehta, John Bent, Aaron Torres, Gary Grider, Edgar Gabriel. High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion: 10-16 Nov. 2012.
Abstract / PDF [296K]
- The Power and Challenges of Transformative I/O. Adam Manzanares, John Bent, Meghan Wingate, Garth
Gibson. 2012 IEEE International Conference on Cluster Computing (CLUSTER), 24-28 Sept. 2012.
Abstract / PDF [319K]
- LDPLFS: Improving I/O Performance Without Application Modification. S.A. Wright, S.D. Hammond, S.J. Pennycook, I. Miller, J.A. Herdman, S.A. Jarvis. 26th IEEE International Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW), 2012. 21-25 May 2012.
Abstract / PDF [469K]
- Storage Challenges at Los Alamos National Lab. John Bent, Gary Grider, Brett Kettering, Adam Manzanares, Meghan McClelland, Aaron Torres, Alfred Torrez. IEEE Conference on Massive Data Storage. April 16-20, 2012. Pacific Grove, CA.
Abstract / PDF [129K]
- Jitter-Free Co-Processing on a Prototype Exascale Storage Stack. John Bent, Sorin Faibish, Jim Ahrens, Gary Grider, John Patchett, Percy Tzelnic, Jon Woodring. IEEE Conference on Massive Data Storage. April 16-20, 2012. Pacific Grove, CA.
Abstract / PDF [269K]
- U.S. Department of Energy Best Practices Workshop on File Systems & Archives: Usability at Los Alamos National Lab. John Bent, Gary Grider. U.S. Department of Energy Best Practices Workshop on File Systems & Archives. San Francisco, CA; September 26-27, 2011.
Abstract / PDF [133K]
- ...And eat it too: High read performance in write-optimized HPC I/O middleware file formats. Milo Polte, Jay Lofstead, John Bent, Garth Gibson, Scott A. Klasky, Qing Liu, Manish Parashar, Norbert Podhorszki, Karsten Schwan, Meghan Wingate, Matthew Wolf. 4th Petascale Data Storage Workshop held in conjunction with Supercomputing '09, November 15, 2009. Portland, Oregon. Supersedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-09-111, November 2009.
Abstract / PDF [388K]
- PLFS: A Checkpoint Filesystem for Parallel Applications.
John Bent, Garth Gibson,
Gary Grider, Ben McClelland,
Paul Nowoczynski,
James Nunez, Milo Polte,
Meghan Wingate. LANL Technical Release LA-UR 09-02117, April 2009.
Abstract / PDF [415K]
- PLFS Traces: PLFS has been used to generate many IO traces of benchmarks and real applications.
Mailing List
Join the PLFS developers mailing list at https://lists.sourceforge.net/lists/listinfo/plfs-devel
Send mail with questions, etc. to plfs-devel@lists.sourceforge.net
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.