Network Bandwidth Management for ML
At the core of Machine Learning (ML) analytics applied to Big Data is often an expert-suggested model, whose parameters are refined by iteratively processing a training dataset until convergence. The completion time (i.e. convergence time) and quality of the learned model not only depends on the rate at which the refinements are generated but also the quality of each refinement. While data-parallel ML applications often employ a loose consistency model when updating shared model parameters to maximize parallelism, the accumulated error may seriously impact the quality of refinements and thus delay completion time, a problem that gets worse at scale. Although more immediate propagation of updates reduces the accumulated error, this strategy is limited by physical network bandwidth. Additionally, the performance of the widely used stochastic gradient descent (SGD) algorithm is sensitive to initial step size, and hand tuning is usually needed to achieve optimal performance.
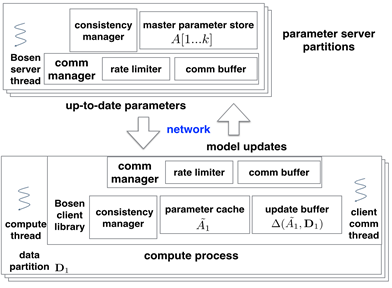
In this work, we consider network bandwidth as a resource for scheduling and our goal is to maximize the utility of the limited network bandwidth for distributed ML training. To achieve this goal, we develop a key-value store for ML training, refered to as Bosen. Such key-value stores developed for ML training are often referred to as parameter server, which provides a coherent distributed shared memory abstraction and hides network communication and consistency management from its applications. To achieve the goals said above, bosen employs rate-limited continuous communication (as opposed to unlimited bursty communication employed by previous examples) and allocate bandwidth based on the importance of the messages to be communicated. Please refer to our publications for more detials.
|
The architecture of Bosen. |
|
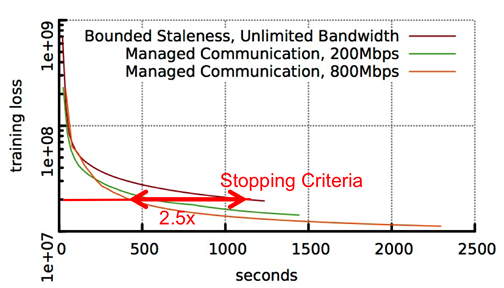
Compare Matrix Factorization with and without managed communication. Additional bandwidth budget can be automatically taken advantage to improve the algorithm convergence rate. |
|
Compare LDA with and without managed communication using different prioritization strategies. Proper prioritization leads to fast convergence with less bandwidth consumption. |

People
FACULTY
Garth Gibson
Eric Xing
Greg Ganger
Phil Gibbons
GRAD STUDENTS
Jinliang Wei
Wei Dai
Henggang Cui
Publications
- Managed Communication and Consistency for Fast Data-Parallel Iterative Analytics
Jinliang Wei, Wei Dai, Aurick Qiao, Henggang Cui, Qirong Ho, Gregory R. Ganger, Phil B. Gibbons, Garth A. Gibson, Eric P. Xing. The 6th ACM Symposium on Cloud Computing (SoCC 2015), Aug 2015. Best Paper Award.
Abstract / PDF [369K]
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Everpure, Google, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Salesforce, Uber, and Western Digital for their interest, insights, feedback, and support.