Exploiting Iterativeness
Many large-scale machine learning (ML) applications use iterative algorithms
to converge on parameter values that make the chosen model fit the input data.
Often, this approach results in the same sequence of accesses to
parameters repeating each iteration.
In this project, we show that these repeating patterns can and should be exploited
to improve the efficiency of the parallel and distributed ML applications
that will be a mainstay in cloud computing environments.
Focusing on the increasingly popular "parameter server" approach to
sharing model parameters among worker threads,
we describe and demonstrate how the repeating patterns can be exploited.
Examples include replacing dynamic cache and server structures with static
pre-serialized structures,
informing prefetch and partitioning decisions, and determining
which data should be cached at each thread to avoid both contention
and slow accesses to memory banks attached to other sockets.
Experiments show that such exploitation reduces per-iteration time
by 33--98%, for three real ML workloads, and that these improvements
are robust to variation in the patterns over time.
|
Two ways of collecting per-iteration access sequences. |

|
(a) PageRank |

|
(b) Collaborative Filtering |
|
(c) Topic Modeling |
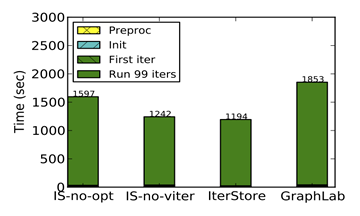
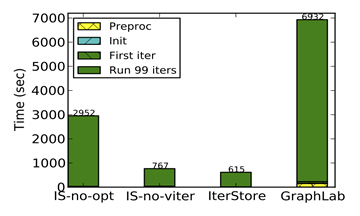
Performance comparison of "IterStore with no optimizations", "IterStore with optimizations but collects access sequences at the first iteration", "IterStore with optimizations and collects access sequences during the virtual iteration", and "GraphLab".
People
FACULTY
Greg Ganger
Phil Gibbons
Garth Gibson
Eric Xing
GRAD STUDENTS
Henggang Cui
Jinliang Wei
Wei Dai
Publications
- Exploiting Iterative-ness for Parallel ML Computations
Henggang Cui, Alexey Tumanov, Jinliang Wei, Lianghong Xu, Wei Dai, Jesse Haber-Kucharsky, Qirong Ho, Gregory R. Ganger, Phillip B. Gibbons, Garth A. Gibson, and Eric P. Xing (SoCC'14)
Abstract / PDF [623KB]
Acknowledgements
We thank the members and companies of the PDL Consortium: Amazon, Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.