GIGA+: Scalable Directories for Shared File Systems
(or, How to Build Directories with Trillions of Files)
Contact: Garth Gibson or
Overview
Traditionally file system designs have envisioned directories as a means of
organizing files for human viewing; that is, directories typically contain
few tens to thousands of entries.
Users of large, fast file systems have begun to put millions of entries in
single directories, probably as simple databases.
Furthermore, many large-scale applications burstily create a file per compute
core in clusters with tens to hundreds of thousands of cores.
This project is about how to build file system directories that contain billions
to trillions of entries and grow the number of entries instantly with all cores
contributing concurrently.
The central tenet of our work is extreme scalability through high parallelism.
We realize this principle by eliminating serialization, minimizing system-wide
synchronization, and using weak consistency semantics for mapping information
(applications and users see a consistent view of the directory contents).
We build a distributed directory index, called GIGA+, that uses a unique,
self-describing bitmap representation that allows the servers to encode all
their local state in a compact manner and provides the clients with hints
required to address the correct server.
In addition, GIGA+ also handles operational realities like client and server
failures, addition and removal of servers, and "request storms" that overload
any server.
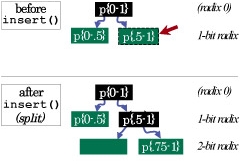
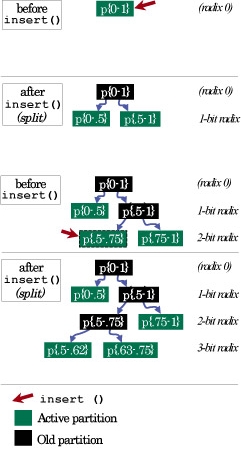 |
Concurrent and unsynchronized growth in GIGA+ directories |
We are building two prototypes of our system. In the first prototype, we have added support for huge directories to an open source, cluster file system called Parallel Virtual File System (PVFS2) that is used in production on large HPC clusters. The second prototype uses the FUSE (File System in Userspace) API to build a user-level implementation of the GIGA+ indexing technique. The goal of this prototype is to develop a "library"-like platform to experiment with ideas to build scalable metadata services and make them portable across various underlying file systems like NFS/pNFS and cluster file systems that don't have support for distributed directories.
Code Releases
We plan to release the source code of our PVFS2 and FUSE prototypes.
Publications
- GIGA+ : Scalable Directories for Shared File Systems.
Swapnil Patil, Garth Gibson. Carnegie Mellon University Parallel Data Lab Technical Report
CMU-PDL-08-110.
October 2008.
Abstract / PDF [400K]
- User Level Implementation of Scalable Directories (GIGA+). Sanket Hase, Aditya Jayaraman, Vinay K. Perneti, Sundararaman Sridharan, Swapnil V. Patil, Milo Polte, Garth A. Gibson. Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-08-107, May 2008.
Abstract / PDF [1.67M]
- GIGA+: Scalable Directories for Shared File Systems. Swapnil V. Patil, Garth A. Gibson, Sam Lang, Milo Polte. Proceedings of the 2nd international Petascale Data Storage Workshop (PDSW '07) held in conjunction with Supercomputing '07. November 11, 2007, Reno, NV
Abstract / PDF [114K]
Acknowledgements
This material is based upon research sponsored supported by the DOE Office of Advanced Scientific Computing Research (ASCR) program for Scientific Discovery through Advanced Computing (SciDAC) under Award Number DE-FC02-06ER25767, in the Petascale Data Storage Institute (PDSI). It is also supported by the Los Alamos National Lab under Award Number 54515-001-07, the CMU/LANL IRHPIT initiative.
We thank the members and companies of the PDL Consortium: American Power Conversion, Data Domain, Inc., EMC Corporation, Facebook, Google, Hewlett-Packard Labs, Hitachi, IBM, Intel Corporation, LSI, Microsoft Research, NetApp, Inc., Oracle Corporation, Seagate Technology, Sun Microsystems, Symantec Corporation and VMware, Inc. for their interest, insights, feedback, and support.
