Otus Monitoring System
We have designed an approach, based on resource attribution, that aims at facilitating performance analyses of distributed data-intensive applications. We implemented a prototype monitoring Otus, which embeds this approach, and attribute resource usage to jobs and services in Hadoop clusters. Otus is now deployed in our production cluster to help users and system administrators with application performance analysis and troubleshooting.
Problem
Our modern world is data led. Distributed data-intensive processing frameworks such as Hadoop, Dryad, Pig and Hive, are now widely used to deal with the data deluge. However, understanding the resource requirements of these frameworks and the performance characteristics of their applications is inherently difficult due to the distributed nature and scale of the computing platform. In a typical data-intensive cluster installation, computations for user jobs are co-located with cluster services. This mode of operation creates complex interactions and poses a considerable challenge for the understanding of resource utilization and application performance. This project aims at attributing resource utilization to user jobs and cluster services at a fine grained level.
Results
The techniques for resource attribution are embodied in a prototype monitoring system implementation named Otus. At a high-level, Otus uses metrics and events from different layers in the cluster software stack, from OS-level to high-level services such as HDFS, Hadoop MapReduce (MR), and Hbase. The data is correlated to infer the resource utilization for each service component and job process in the cluster. To effectively present these metrics to users, a flexible analysis and visualization system is provided to display the performance data using different selection and aggregation criteria. We have deployed our prototype on a 64-node production cluster. We have used Otus to find out bugs in the current version of Hadoop MapReduce frameworks. Otus also helped us to analyze performance of serveral cloud services running in our cluster.
Challenge
The future direction is to attribute resource utilization to requests of file and database systems (e.g. HDFS, HBase). A possible approach is to use end-to-end tracing technology to get resource usage incurred by a request. Another challenge is to enable the scaling of the storage back-end in order to preserve historical metrics. We are exploring alternative such as OpenTSDB and HBase. The key problem is to design an efficient schema that enables efficient insertion and query over the data.
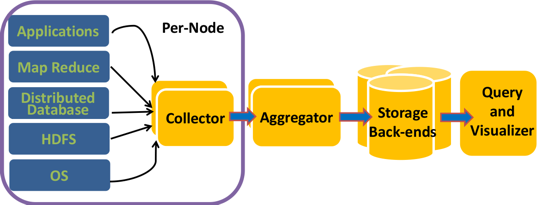
The architecture of the Otus monitoring system.
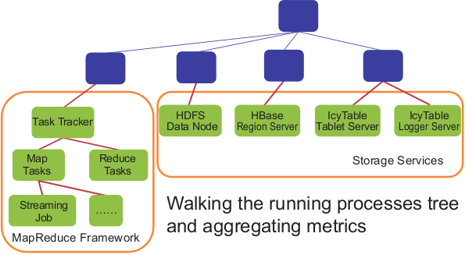
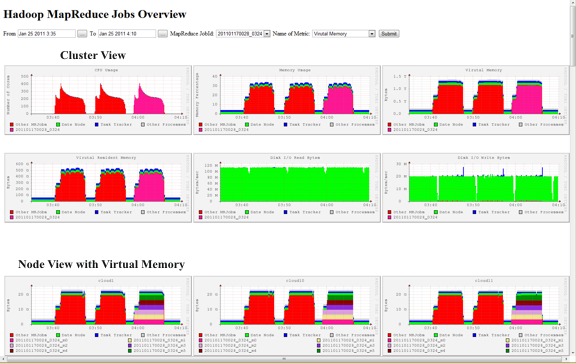
This figure shows the web GUI of Otus. The web page gives resource utilization of a particular MapReduce job A. It mainly consists of two parts: cluster view and node view. The cluster view gives the utilization aggregated over all nodes that run the job A. The node view gives detailed resource utilization of processes of interest in every node that runs job A.
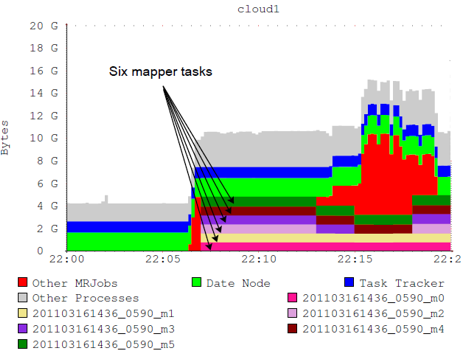
This figure shows the memory resource utilization in a particular node of our cluster.
It shows the memory usage of different processes including MapReduce tasks, job tracker,
HDFS data node, etc.
People
FACULTY
Garth Gibson
Julio López
GRAD STUDENTS
Kai Ren
Publications
- Otus: Resource Attribution in Data-Intensive Clusters. Kai Ren, Julio López, Garth Gibson.
MapReduce'11, June 8, 2011, San Jose, California, USA. Supercedes Carnegie Mellon University Parallel Data Lab Technical Report CMU-PDL-11-106, April 2011.
Abstract / PDF [2.5M]
Software Releases
Acknowledgements
This work is supported by The Gordon and Betty Moore Foundation, the National Science Foundation under award CCF-1019104, and the Qatar National Research Foundation under award 09-1116-1-172.
We thank the members and companies of the PDL Consortium: Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Labs, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., Uber, and Western Digital for their interest, insights, feedback, and support.