STRADS: Model Parameter Scheduling
Machine learning problems with big-data and big-model lead us to parallel computing. Speedup of parallel machine learning depends on how we parallelize ML algorithm and underlying distributed framework performance. In tranditional data-parallel approach, we have used relaxed consistency such as SSP that reduces synchronization cost, mitigates straggler effects, and finally improves iteration throughput. However, it causes inconsisteny on the shared model parameters. The inconsistent shared parameter values might hurt accuracy of computation and increse the number of updates until ML algorithm converges. This inconsistency problem often limits speedup of parallel machine learning in a distributed environment.
In this work, we takes a comprehensive approach that considers machine learning and system at the same time. On the machine learning side, we present SchMP (Scheduled Model Parallelism) scheme that schedules model parameters to avoid concurrent updates of dependent model parameters, which eliminates or reduces inconsistency of shared model parameters. On the system side, STRADS execution engines implement several system optimizations that overlap scheduling, network communication and parameter update computation in order to improves update throughput without hurting progress per update too much. We present two common scheduling schemes: (1) dynamic-scheduling; (2) static-scheduling. Dynamic-scheduling is the by-default scheme that analyzes dependency structure and conducts priority sampling based on changes of parameter values in runtime. On contrary static-scheduling makes a complete schedule plans prior to runtime. In some ML applications, dependency structure shows regularity and it's possible to make a schedule plan before runtime. For these ML applications, static-scheduling could be more beneficial than dynamic-scheduling because it does not incur runtime scheduling overhead. Due to the different characteristics of two scheduling schemes, we implemented two different execution engines: (1) STRADS-Dynamic engine; (2) STRADS-Stratic engine. For performance benchmark, We implement lasso, logistic regression and support vector machine on STRADS-Dynamic, and SGD-MF, CD-MF and LDA on STRADS-Static. We observed that SchMP ML applications running on STRADS engines outperform parallel ML implementations without model parameter scheduling. For instance, SchMP-LDA and SchMP-Lasso achives 10x and 5x faster training speed than well-established baselines.
|
Convergence time: SchMP-Lasso vs YahooLDA |
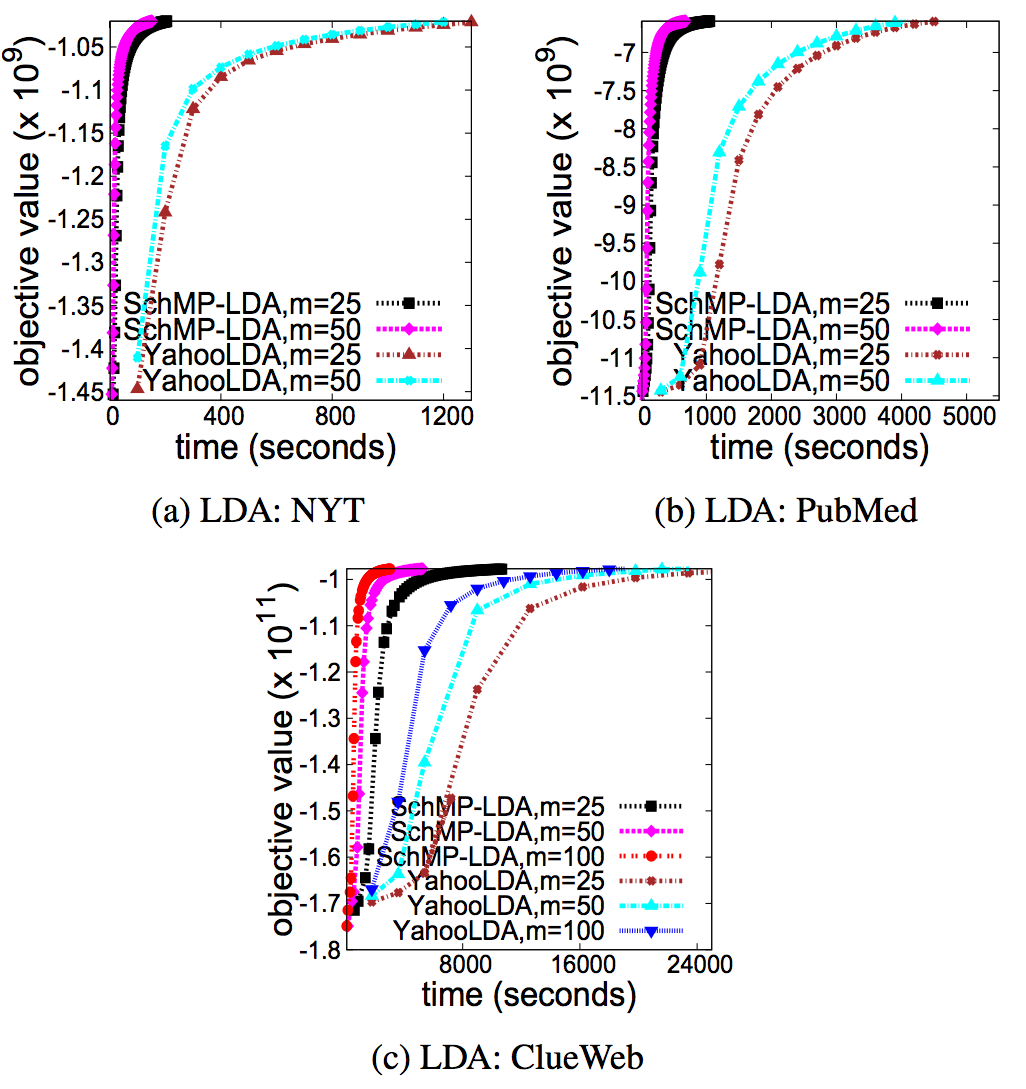
|
Convergence time: SchMP Matrix Factorization |
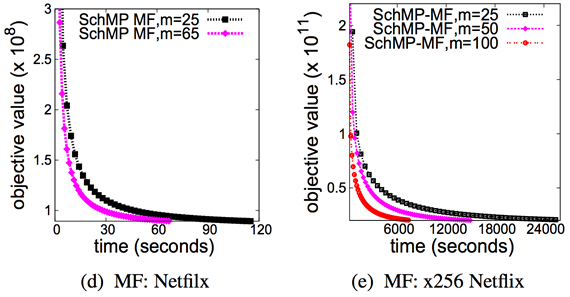
|
Convergence time: SchMP-Lasso vs Shotgun Lasso |
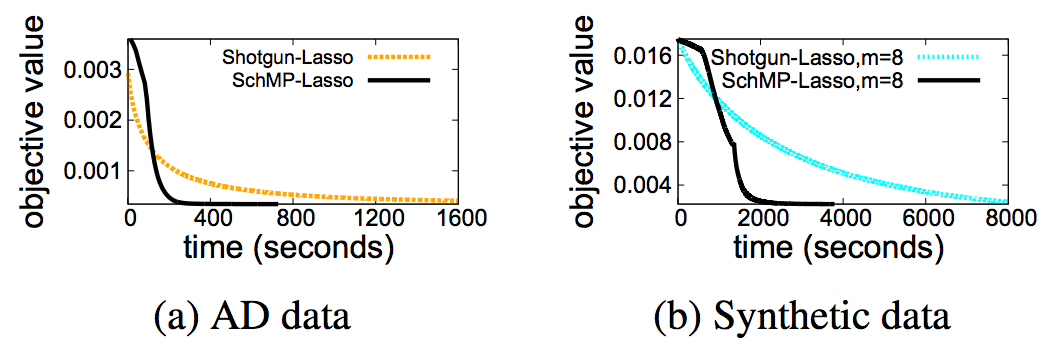
People
FACULTY
Garth Gibson
Eric Xing
GRAD STUDENTS
Jin Kyu
Kim
Xun Zheng
Wei Dai
Publications
- STRADS: A Distributed Framework for Scheduled Model Parallel Machine Learning. Jin Kyu Kim, Qirong Ho, Seunghak Lee, Xun Zheng, Wei Dai, Garth A. Gibson, Eric P. Xing. ACM European Conference on Computer Systems, 2016 (EuroSys'16), 18th-21st April, 2016, London, UK.
Abstract / PDF [1.6M]
Acknowledgements
We thank the members and companies of the PDL Consortium: Bloomberg LP, Datadog, Google, Intel Corporation, Jane Street, LayerZero Research, Meta, Microsoft Research, Oracle Corporation, Oracle Cloud Infrastructure, Pure Storage, Salesforce, Samsung Semiconductor Inc., and Western Digital for their interest, insights, feedback, and support.